遇到文件檔全文檢索需求,打算用 SQL Server 全文檢索或 lucent.net實現,無論使用何者都免不了從 Word、Excel、PowerPoint 或 PDF 檔萃取純文字內容建立索引的程序。經簡單評估,使用微軟的 IFilter 介面應是較簡單可行的做法。搜索引擎面對的檔案種類五花八門,不太可能涵蓋各種檔案格式,知道從中取出文字內容的方法,IFilter 制定統一程式介面,不管檔案格式為何,只要廠商或第三方有提供專屬 IFilter,搜尋引擎便可使用呼叫統一的 API 方法傳入檔案名稱取得文字內容,再為文字建立索引方便日後查詢。
專案面臨的檔案種類還算單純,只需涵蓋 Office 文件及 PDF 檔,而二者都有現成的 IFilter 可用:
- PDF iFilter 64 下載
- Office 2010 Filter Packs 下載
包含 Legacy Office Filter (97-2003; .doc, .ppt, .xls)、Metro Office Filter (2007; .docx, .pptx, .xlsx) 、Zip Filter、
OneNote filter、Visio Filter、Publisher Filter、Open Document Format Filter
有 32/64 版本可選擇,由於 PDF iFilter 為 64,建議 Office Filter 也裝 64bit
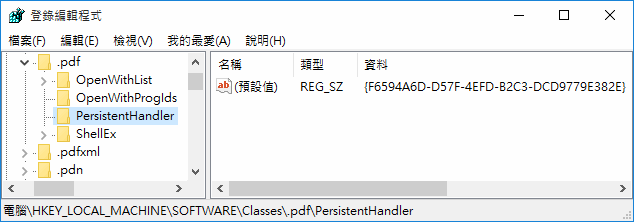
簡單如何說明由 Registry 找出副檔名對應 IFilter 的原理。首先在 NTLM\SOFTWARE\Classes\.副檔名 可以找到 PersistentHandler 機碼,預設值指向一個 GUID:
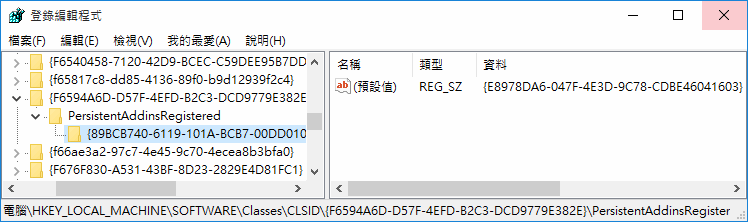
在 NTLM\SOFTWARE\Classes\CLSID\{PersistentHandler GUID}\PersistentAddinsRegistered 可以找到名稱是 GUID 的機碼,預設值再指向另一個 GUID:
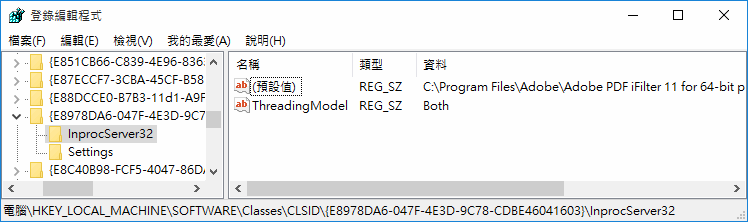
繼續在 CLSID 找尋該 GUID,InprocSever32 預設值即指向其 IFilter DLL: (下圖以 PDF iFilter 11 為例)
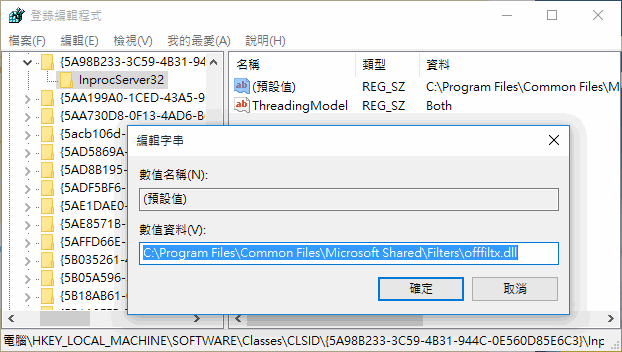
同理,我們也能找到 Office Filter 的實際位置:
上述的 Registry 大地遊戲過程有點繁瑣,加上爬文發現 PDF iFilter 有些眉角要克服,我找到網友寫好的懶人包元件(參考: Adobe PDF IFilter 11 - My Technical Diary),經實測只需幾行程式可通吃 Office/PDF,方便許多。
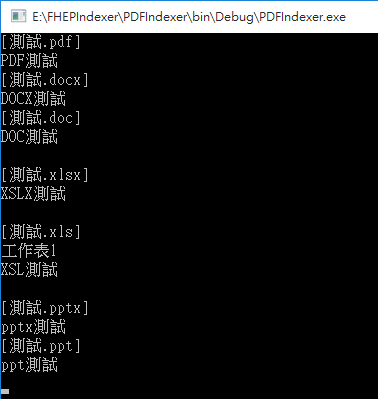
為了測試,我準備了doc, docx, ppt, pptx, xls, xlsx, pdf 七種檔案,內容都只有單純一行"XXXX測試"字樣。
程式如下:
[STAThread]
staticvoid Main(string[] args)
{ List<string> names = "測試.pdf,測試.docx,測試.doc,測試.xlsx,測試.xls,測試.pptx,測試.ppt" .Split(',').ToList();names.ForEach(f =>
{ Console.WriteLine($"[{f}]"); using (var reader = new EPocalipse.IFilter.FilterReader($"e:\\tests\\{f}"))
{ string text = reader.ReadToEnd(); Console.WriteLine(text);
}
});
Console.Read();
}
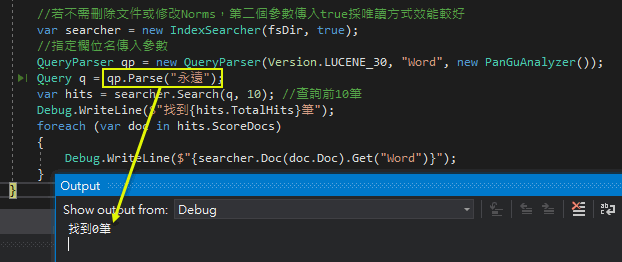
測試成功!