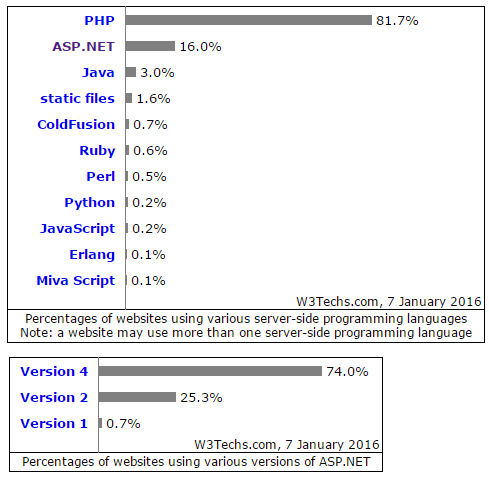
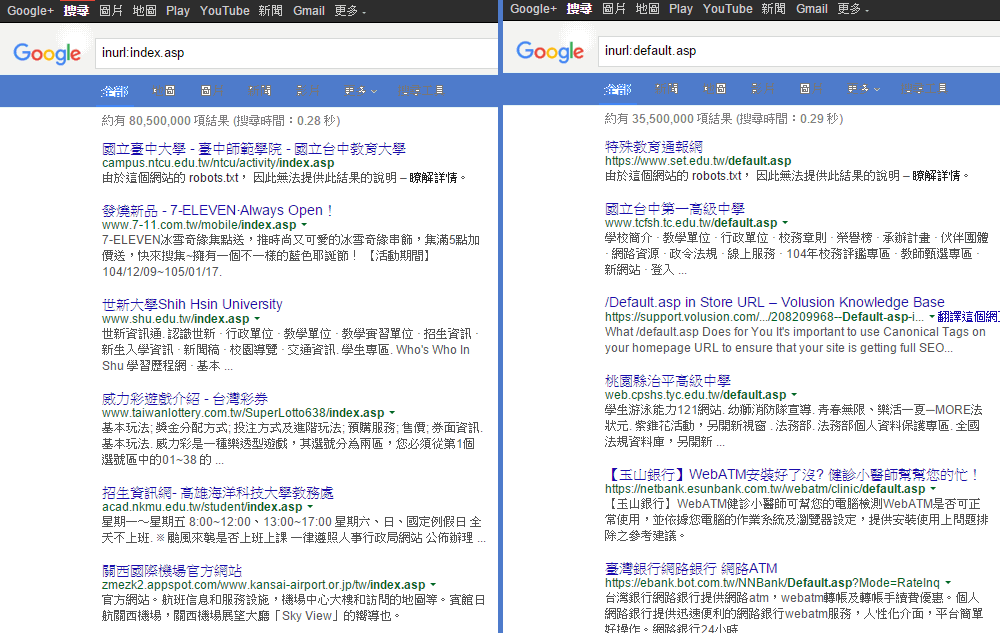
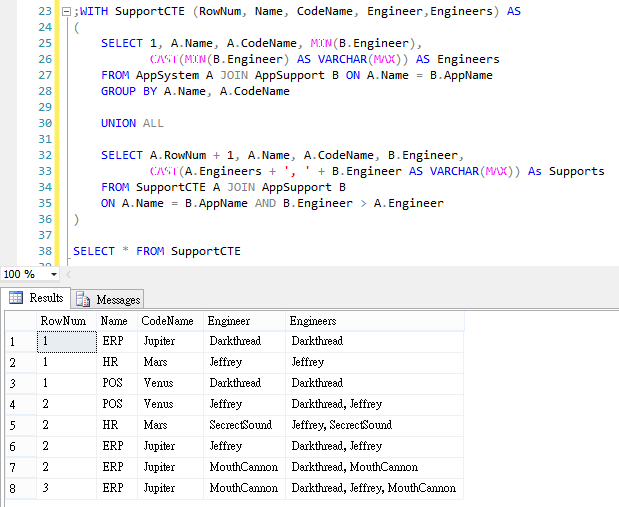
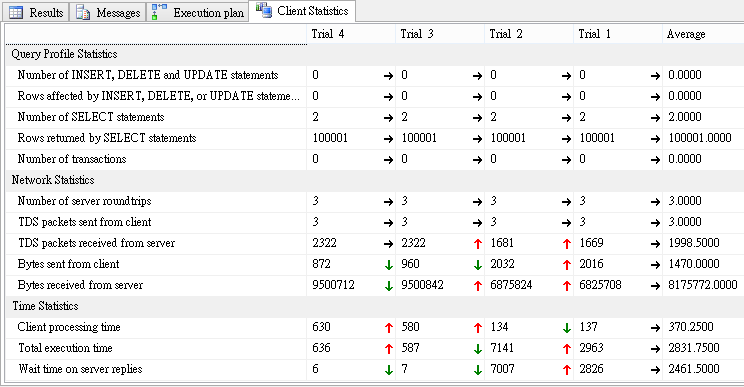
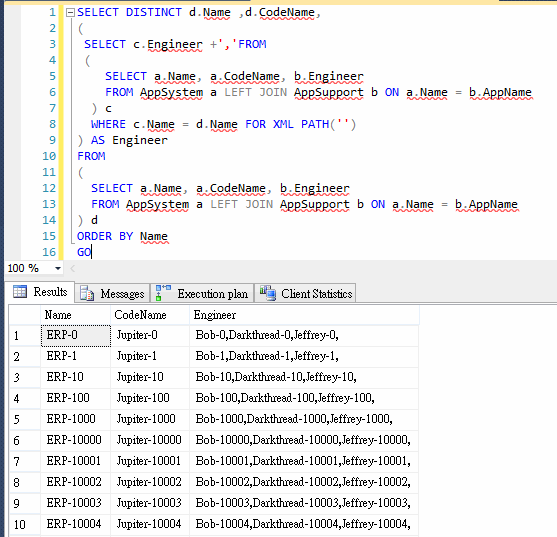
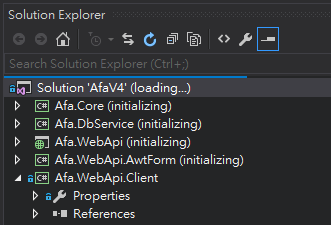
在臉書專頁留言區看到一則帳號停權通知,心頭一驚:

Last Warning, Your account will be disabled permanent because your accouts have been reported by other users,And another reason is not allowed on Facebook… 留言者取名Facebook Pages,又配上臉書Logo,留言內容大意是我的帳號因為被人檢舉即將被永久停權,下方有一個連到Facebook Pages臉書專頁文章的連結:

這裡面有更詳細的說明,提到我的專頁被人檢舉違反使用協議,將導致停用,需要驗證電子郵件信箱以示清白,並在底下列了網址驗證帳號以證明所有權,若不依指示,專頁將被永久刪除並無法還原。循著網址出現以下輸入帳號、密碼跟生日的登入頁面:

一路上都是臉書的網址、名稱跟標示,加上被警告將要被停權,當時人在外面從平板收到訊息,差點下意識就要敲帳號,不過大腦讀取帳號、密碼時觸發了人體資安模組,警鈴大作,仔細一看,這網址有問題呀!pages-help. tuars.com不是臉書的網域,莫非是「釣魚網站」!(要騙取訪客輸入帳號及密碼,以竊取臉書資料或冒用身分)
回家後再仔細查證,愈看愈有問題。首先,官方的停用通知怎麼會用留言方式遞交?而且說明文字有些文法及排版錯誤。再者連到所謂的Facebook Pages專頁,專頁今天才成立,第一篇文章就是第二張圖的停權通告,之後有幾篇五花八門的分享文章,都指向第一篇停權公告,猜想它還在別人的專頁上留言,目的在引誘專頁所有者或網友看到停權公告連到上圖的假登入畫面以騙取帳號。

猜想這種做法很快就會被官方發現下架,有可能是想打閃電戰,或者關閉後依然可以用同樣手法另起爐灶再戰,很難杜絕。
在此提醒大家:在Facebook上看到你帳號將被停權的警告訊息或電子郵件通知,請仔細求證,不要胡里胡塗地看到網頁有帳號、密碼輸入欄就敲,以免中計帳號被盗。