同事遇到集保罕集問題,我試著解釋個中奧妙時冒出一堆「集保罕字的X」「Unicode標準字的X」「看起來一樣但編碼不同」把同事薰得七葷八素,感覺都快吐了… 嗯,寫篇文章細說從頭吧。
很久很久以前,在 Unicode 還沒一統天下之前,BIG5是台灣地區的主流中文編碼,其中定義 13,053 個常用字與次常用字與 441 個符號。問題來了,有些日常生活會用到的字(最常見是人名)沒被包含在這一萬三千字裡,所以早些年水牛伯還活躍於政壇時不時可在使用 BIG5 的新聞網站看到「游錫方方土」,還有「陶吉吉」大家應該也不陌生 XD (關於 BIG5 與 Unicode 編碼,之前曾在中文編碼解析工具介紹文提過,維基百科則有更完整說明,有興趣深入可以一讀)
當今解決 BIG5 缺字問題最有效做法是回歸王道-改用 Unicode,Unicode 可正確處理七萬個漢字,幾乎不會再有缺字困擾。但對現有系統或資料庫,更換資料編碼是動搖國本的大事,只能在繼續使用 BIG5 前題下克服缺字問題,於是造字區成了唯一救贖。
BIG5 當初在制定時,編碼範圍保留了三段造字區:FA40-FEFE 785字 + 8E40-A0FE 2983字 + 8140-8DFE 2041字, 共可再自訂 5809 字 。

圖片來源:CNS11643 中文全字庫-認識全字庫-中文碼介紹
集保公司所推出的集保罕用字集(下載位置:其他類別/華康中文罕用字型)就是透過造字解決 BIG5 缺字問題。
把鏡頭拉近一點看個實例,集保罕用字集下載檔中有個 Map_code.txt,裡面有所有造字的內碼對照表,我們就拿三條魚的「鱻」字當範例:
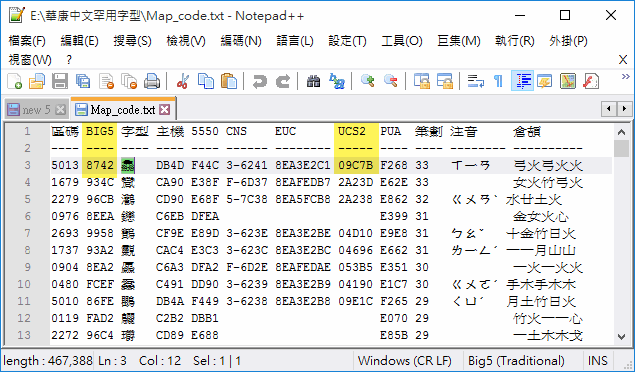
罕用字集中造了鱻字,BIG5 碼為 8742,落於 8140-8DFE 造字區,是一個合法的 BIG5 字元,也能被轉換成 Unicode,UCS2 編碼(固定用兩個 Byte 表示一個字元的編碼系統)為 F268。但 Windows 內建的新細明體、標楷體、正黑體並沒有為 UCS2 編碼 F268 繪製字型,因此不另外安裝專屬字型就看不到造字區字元。上面圖示所用電腦裝了華康罕用字型,所以才看得到綠底標示位置的「鱻」字,一般電腦看到的會是空白。回到 Unicode 端,Unicode 的編碼系統可容納七萬個漢字,當然也有「鱻」字(不然大家讀這篇文章時不會看到它),而它的 UCS2 碼是上圖中的 9C7B。
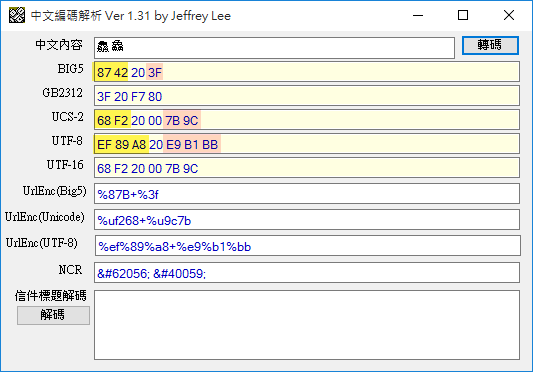
用中文編碼解析工具分析一下會更清楚。如下圖,我們輸入兩個鱻字,中間夾一個空白,第一個為集保造字(黃底),第二個為 Unicode 內建字(粉紅底),二者的 BIG5 編碼分別為 8742 與 3F(Unicode 鱻對應不到有效 BIG5 編碼故變成問號,ASCII 碼為 3F),其 UCS-2 則分別為 F268 及 9C7B,印證前一段的說明。
這裡先簡單做個總結:在 Windows 要處理罕用字有兩種選擇:1) 使用 Unicode 版字元 2) 要求使用環境部署罕用字型,使用造字版本字元。當你的系統身處使用 BIG5 造字處理缺字問題的環境,就必須面對明明同一個字卻有兩種編碼的狀況。
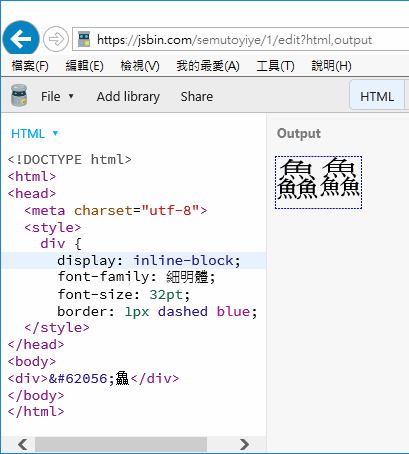
在已安裝罕用字集的電腦可同時看到 Unicode 版與造字版字元,實務上二者看起來有差異,如下圖所示,網頁同時放入兩種版本的鱻(造字版輸入法不易選取,故我用表示之),字型都指定為「細明體」,使用瀏覽器檢視時可看左邊的造字版字型比 Unicode 版高,二者明顯不同。
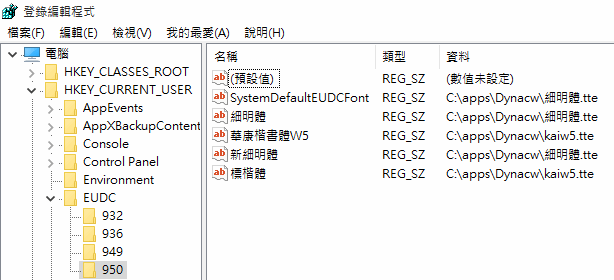
為什麼同樣是細明體,卻感覺是不同的字體?安裝罕用字型後,會有以下 EUDC(End User Defined Characters ) Registry 指定支援造字區的專用字型,以告知軟體在字型遇到造字區字元時該使用何種專屬字型替代。以上圖為例,左邊來自華康字型(細明體.tte),右邊來自系統原本的細明體 ,故字高及樣式有所差異。(實測發現不同軟體處理原則有別,顯示結果可能不同)
介紹完集保罕用字原理與特性,來談談設計系統應如何因應。我建議-除非系統被限制必須維持 BIG5 編碼,系統從資料庫、檔案格式到程式 UI 一律改用 Unicode 才是王道,採行統一標準,才不會冒出一堆轉換需求。如此要面對的問題只剩:「萬一使用者裝了罕用字集在 UI 輸入造字區字元怎麼辦?」,解決之道要在使用者可能輸入罕用字的地方加上檢查(依經驗大概只有姓名地址),阻止使用者輸入造字區字元或是偷偷將其置換成 Unicode 版本,前面提到的 Map_code.txt 已提供足夠資訊要偵測或轉換程式不難。確保進入系統的永遠只有 Unicode 標準字,就不會傷了皇城內的和氣囉~